

Authorship: The Identity Primitive Every Enterprise Should Demand From the Agents It Deploys
AuthR makes authorship a verifiable identity primitive alongside AuthN and AuthZ, so enterprises can trace who answers when an AI agent acts.


Last month, in CIO, I argued that identity as we know it is dying, and that AI governance now starts with lineage, not logins. That piece was a thesis. It named the problem: when AI entities act, decide, and speak on your organization’s behalf, access stops being the point, and authorship takes over.
This is the answer to that thesis. AuthR, short for Authorship Representation, is a
The Third Pillar of Identity Just Shipped

Thanks for reading The Strategy Layer! Subscribe for free to receive new posts and support my work.
proposed framework that makes authorship a verifiable layer in the identity stack, alongside authentication and authorization rather than bolted on after the fact. The CIO piece ended on a single line: every AI entity you deploy carries a lineage, and the companies that can trace that lineage will govern it. AuthR is how you trace it.
I am publishing this the week the identity community convenes at Identiverse, where, for the first time, there is a dedicated Non-Human and Agentic AI Identity track and a pavilion to match. The agenda has caught up to the problem. What the conversation behind it needs is an operating model for accountability. That model is authorship.
From access control to authorship
For two decades, identity and access management has answered two questions. Who are you, and what are you allowed to do. Authentication and authorization. They were built for a world where a human sat at a keyboard, signed in, and performed a discrete action they were accountable for by default. The human was the author, because the human was the only thing in the loop.
Agentic AI breaks that assumption quietly. An orchestrator delegates to a sub-agent, which delegates to a tool, which calls a service, across a workflow that runs for hours and re-plans itself as conditions change. Every hop carries a valid token. Every call is in scope. And nowhere in that chain is there a field that says whose judgment this was, or whether the action still reflects what a human actually authorized.
That is the gap. Authentication proves who is present. Authorization proves what access was granted. Neither proves whose judgment was represented, or who is responsible when an in-scope action serves a goal no human ever set. As enterprises move from AI that assists to AI that executes, that third question stops being academic and becomes the one the audit committee, the regulator, and the incident responder all ask first.
Authentication proves who. Authorization proves what. Authorship proves whose judgment, and who answers for it. The first two were enough when humans pushed the buttons. They are not enough when agents do.
A maturity model for agentic accountability
The useful way to think about this is not a binary, accountable or not, but a maturity scale. Four rungs, defined by what an auditor or an incident responder can actually reconstruct after an agent acts.
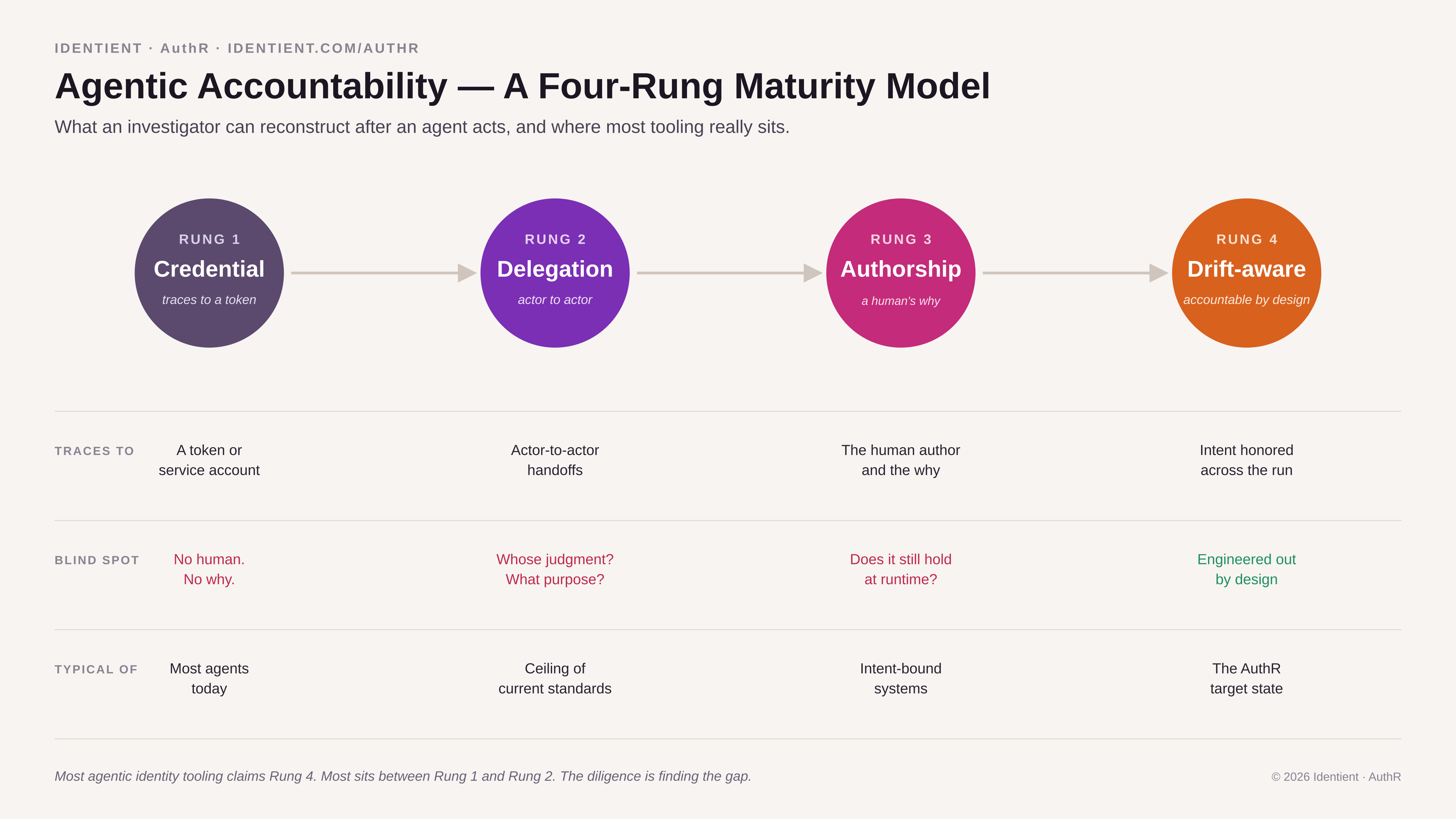
Rung 1 — Attributed to a credential. The action traces to a token or a service account. You know a call was made and which machine identity made it. You cannot say which human stood behind it or why. Most agent deployments live here today. An investigator accepts this only because there is nothing better on offer.
Rung 2 — Attributed to a delegation chain. The action traces back through the hops, actor by actor, using mechanisms like token exchange and on-behalf-of. You can see that an orchestrator delegated to a sub-agent. This is real progress, and it is roughly the ceiling of what current standards provide. But the chain records who passed the baton, not whose judgment authorized the run, and not whether the result still matches the original purpose.
Rung 3 — Bound to a human author and intent. A grounded human author mints a signed root record. The original purpose, the why, travels as a first-class object across every hop. Scope can only narrow downstream, never widen. Now an in-scope action that contradicts the authored intent is visible, because there is an intent to compare it against.
Rung 4 — Continuously evaluated against drift, with revocation supremacy. The gap between original intent and runtime behavior is monitored as a live condition, not a decision settled once at grant time. When an agent re-plans, accumulates memory, or is reshaped by external data far enough from its mandate, the system flags it for re-anchoring or human review. A single revocation signal shortcuts the entire chain and invalidates authorship at every enforcement point at once. This is authorship engineered into the design, not reconstructed after an incident.
Map the agentic identity tooling you are being shown against this scale and the pattern rhymes with every maturity model: the decks claim Rung 4, the products sit between Rung 1 and Rung 2. That gap is where the diligence happens.
What this looks like when the threat is real
The reason this is not a thought experiment is that the failure mode already has CVE numbers.
In June 2025, researchers disclosed EchoLeak, a zero-click attack on Microsoft 365 Copilot. A single crafted email caused the agent to read internal files and exfiltrate them, with no user interaction. The researchers named the failure an LLM Scope Violation: untrusted external input steering an agent into accessing and revealing data it was fully authorized to touch. Every permission check passed. The compromise rode entirely on actions that were in scope.
Seven months later the class returned. Microsoft assigned a new CVE for the same pattern in its agent-building platform, and in that case the vendor’s own data-loss controls flagged the request while the data moved anyway, because it traveled on an authorized action. OWASP now ranks this pattern, Agent Goal Hijack, as the leading agentic risk for 2026.
Notice what none of the existing rungs would have caught. The credential was valid. The delegation chain was intact. Scope never escalated. The only thing that was violated was the user’s intent, and intent was the one thing nothing in the stack was carrying. That is the precise gap AuthR’s intent and drift primitives exist to close, and it is why the answer has to be structural rather than another patch on another path.
Regulators have already named it in the same language. The 2026 FINRA Annual Regulatory Oversight Report lists among its leading generative-AI risks that agents may act beyond the user’s actual or intended scope and authority. When the regulator and the attacker are describing the same failure, the layer that closes it is no longer optional.
What to ask every agentic vendor at Identiverse
Three questions. Useful in any booth conversation this week.
One. Show me where the human author is bound. Not the service account, not the token. The grounded human whose judgment this agent represents. If the vendor can only show you a machine identity, the agent is at Rung 1 or 2, and accountability stops at a credential.
Two. Show me the intent, and show me drift. Ask to see where the original purpose of a workflow is recorded as a first-class object, and how the system detects when runtime behavior has wandered from it. If the answer is scope and policy alone, you have boundaries, not authorship. Boundaries tell you what the agent can do. They do not tell you whether what it is doing still reflects what was asked.
Three. Show me revocation across the whole chain. Pick a delegated, multi-hop workflow. Ask how a single revocation invalidates authorship at every downstream enforcement point at once, not system by system, after the fact. If revocation is a reconstruction project, accountability is too.
These three will sort the room.
Where AuthR sits, plainly
AuthR is a proposed framework, published at v0.1, and I am deliberately precise about what it is and is not. It does not replace authentication or authorization. It is designed to complement existing standards and infrastructure, OAuth, SAML, OIDC, SPIFFE/SPIRE, verifiable credentials, and the agentic-identity work emerging from CoSAI. It adds one layer those mechanisms structurally cannot provide: a verifiable record of who authored a decision, what executed it, why, within what boundaries, shaped by what lineage, and whether conditions drifted far enough to require review.
It is also one layer, not the whole stack. Least privilege, input handling, outbound controls, and runtime monitoring all still belong in the defense. There are credible voices who argue that intent is hard to evaluate deterministically, and they are right that no single control closes the gap. AuthR’s claim is narrow and, I think, defensible: authorship is the layer that travels with the action and answers the question the others cannot, and the field is converging on the idea that intent is becoming the new perimeter. AuthR v0.1 makes that concrete enough to test, challenge, and build on.
the field is converging on the idea that intent is becoming the new perimeter.
The materials, a working paper, draft specification, schema, an interactive playground, and reference implementation resources, are open for exactly that. This is an invitation to the identity and security community to help shape the structure, not a finished product pretending it is done.
At Identiverse this week?
I am not on the floor at Mandalay Bay this year, but I am running virtual briefings all week, June 15 to 18, for anyone working the same problem from the inside: identity architects, CISOs, CIOs, AI governance leads, standards contributors, and the vendors building in the Non-Human and Agentic AI Identity track.
If you want to walk the AuthR maturity model against your own agentic stack, see the CFO wire-transfer scenario run live in the playground, or just argue with the assumptions, I would genuinely welcome the conversation. A briefing, a demo, or a 15-minute chat with no deck. Bring your hardest objection.
Review the AuthR v0.1 materials at identient.com/authr or send an email to steve@identient.ai to request a briefing. The agenda has finally named the problem. Let’s talk about who answers for it.
Steve